What Is the ETL Process in a Data Warehouse and How Does It Work?
As business operations create increasing amounts of big data, stakeholders are finding it more difficult to make informed decisions without cloud-based data warehouses and data visualization tools. Today we talk about the ETL process of collecting, transforming, and migrating data to a data warehouse.
Traditional ETL process vs. data warehouse ETL process
Traditional ETL
Data warehouse ETL
How does ETL process in a data warehouse work?
Extraction
Transformation
Loading
Top 5 benefits of the ETL process
What is the difference between ETL and ELT?
Wrapping up
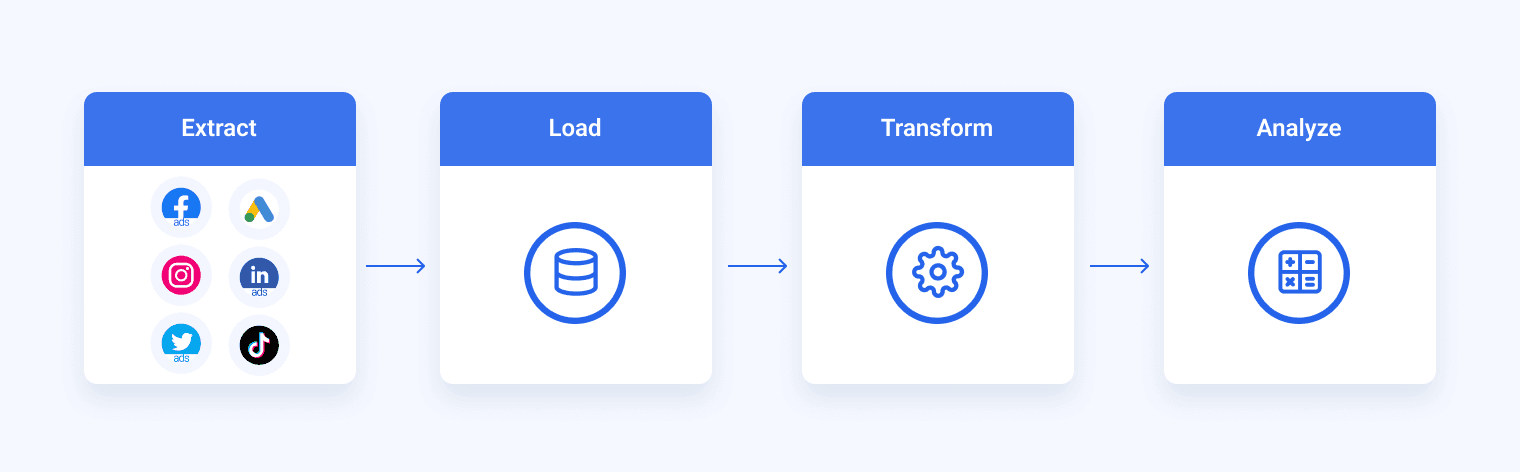
What is the ETL process?
The ETL process is a process where you extract data from various data sources, transform it into a format suitable for loading into a data warehouse, and then load it.
Extract: The first stage is to extract data from different sources, such as transactional systems, spreadsheets, and flat files. This step includes reading data from the source systems and storing it in a staging area.
Transform: In this stage, the extracted data is transformed into a format that is suitable for loading into a data warehouse. This stage includes data cleansing and validating the data, converting data types, combining data from multiple sources, and creating new data fields.
Load: This stage involves loading the transformed data into the data warehouse by creating physical data structures.
The ETL process is repeated as you add new data to the warehouse. The process is essential for data warehousing because it guarantees that the data in the data warehouse is accurate, complete, and up-to-date. It also ensures that the data is in the format required for data analytics and reporting.
Historically, the ETL was a painstaking and time-consuming process that bound whole teams of tech. Luckily, now there are many ETL tools that automate and simplify the ETL process.
One of those tools is Whatagraph.
Whatagraph is specially designed two types of users in mind – both of who need a fast and reliable way to load data from various sources into a central repository:
Small non-tech teams
Marketing agencies that handle hundreds of accounts, each with their own data stacks
Our data transfer process is so simple that anyone can complete it in a few clicks.
Traditional ETL process vs. data warehouse ETL process
Traditional ETL
In a traditional ETL process, data is extracted from online databases, CRM systems, or on-premise data stores, which often have a high throughput and large numbers of read and write requests.
As this source data is not suitable for data analysis or business intelligence (BI) tasks, it is transformed into a staging area. This data transformation involves both cleansing and optimizing data for analysis. The transformed data is then loaded into an analytics database.
This is where business intelligence teams can run queries on that data and present the results to end users or individuals responsible for making business decisions.
The transformed data can also be used as input for machine learning workflows or other data science uses.
A major problem with the traditional ETL process is that analytics database summaries can’t support the type of analysis that teams need, so the whole process needs to run again, with different transformations.
Data warehouse ETL
Analytics powerhouses like Google BigQuery, Snowflake, and Amazon Redshift have changed most organizations' approach to ETL.
These cloud-based analytics databases have enough horsepower to perform transformations in-house rather than requiring a special staging area.
Another reason for the shift to data warehouse ETL is that businesses today increasingly depend on cloud-based SaaS applications that store and operate large amounts of business-critical data, which is accessible through APIs.
Also, data today is often analyzed in raw form, which requires a lightweight, flexible, and transparent ETL system that looks like this:
The biggest advantage of the data warehouse ETL is that transformations and data modeling takes place in the SQL analytics database. This gives BI teams, data engineers, and analysts much greater control over how they work with data and a common programming language they all understand.
How does ETL process in a data warehouse work?
Let’s now break down the three letters in the ETL process and explain how each of those steps works.
Extraction
This isn't the first step of the ETL process. In this step, data from diverse source systems is extracted into the staging area. This data can be in various formats, like relational databases, No SQL, XML, and flat files.
Aggregating this data in the staging area first and not loading it to the data warehouse directly is important because the extracted data is in various formats that are not compatible with each other but can also be corrupted.
Loading into a data warehouse directly may damage the data and make further data management more difficult.
Transformation
This is the second step of the ETL process, which determines the sets of rules or functions on the extracted data to convert it into a single standard format.
Filtering — loading only certain attributes into the data warehouse.
Cleaning — filling up the NULL values with default values, mapping similar entries like U.S.A., United States, and America into the USA, etc.
Deduplication — excluding or discarding redundant data.
Joining — merging multiple attributes into one.
Splitting — splitting a single attribute into multiple attributes.
Sorting — sorting different types of data on the basis of some attribute.
Loading
The third and final step of ETL data processing is to load the changed data into the data warehouse. In some use cases, data can be loaded into the data warehouse very frequently and sometimes after long but regular intervals. The load process rate and period depend on the business needs of individual users and their data systems.
ETL processes can also use the data pipeline concept. This means that as soon as some data is extracted, it can be transformed, and during that time, some new data can be extracted. While the transformed data is being loaded into the data warehouse, the already extracted data can be transformed in real-time.
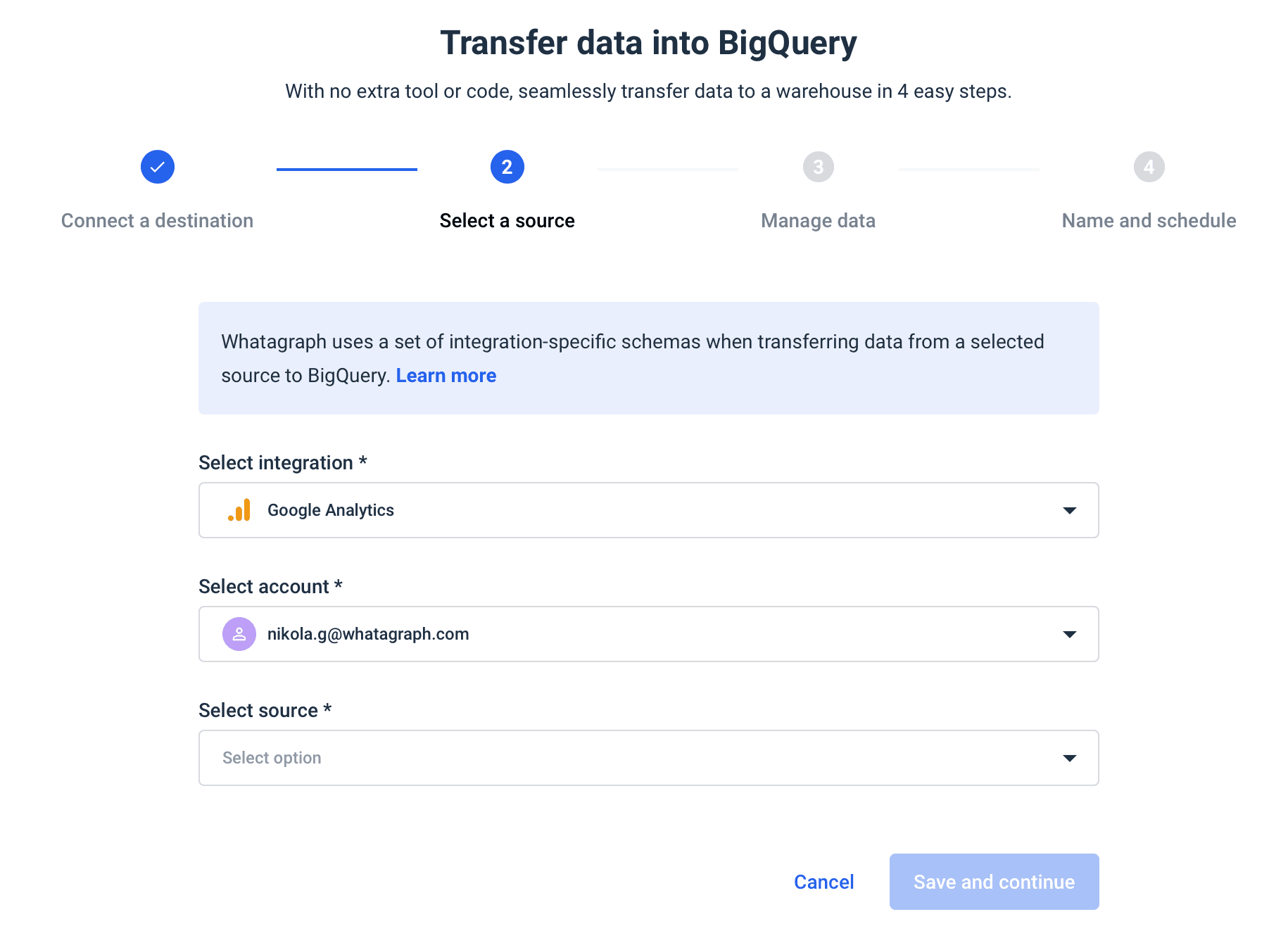
Whatagraph is an automated data pipeline that allows you to load data from multiple sources and connectors to your BigQuery data warehouse.
The data transfer service is already available from the basic pricing plan and takes only four steps to complete:
as the number of sources and the volume of your data grows, Whatagraph scales with your needs.
If you need to report on your BigQuery data, Whatagraph helps you create interactive dashboards that you can fully customize with the relevant metrics and dimensions.
Top 5 benefits of the ETL process
Better data quality: ETL process guarantees that the data in the data warehouse is accurate, complete, and up-to-date.
Improved data integration: ETL pipelines integrate data from multiple sources and systems so your teams can access and use it.
Higher data security: ETL process improves data flow security by controlling access to the data warehouse and ensuring that only authorized users can access the data.
Increased scalability: ETL process is highly scalable as it gives enterprises a means to manage and analyze large data sets.
Improved automation: ETL solutions help automate and simplify ETL processes, cutting the time and effort needed to load data in the warehouse.
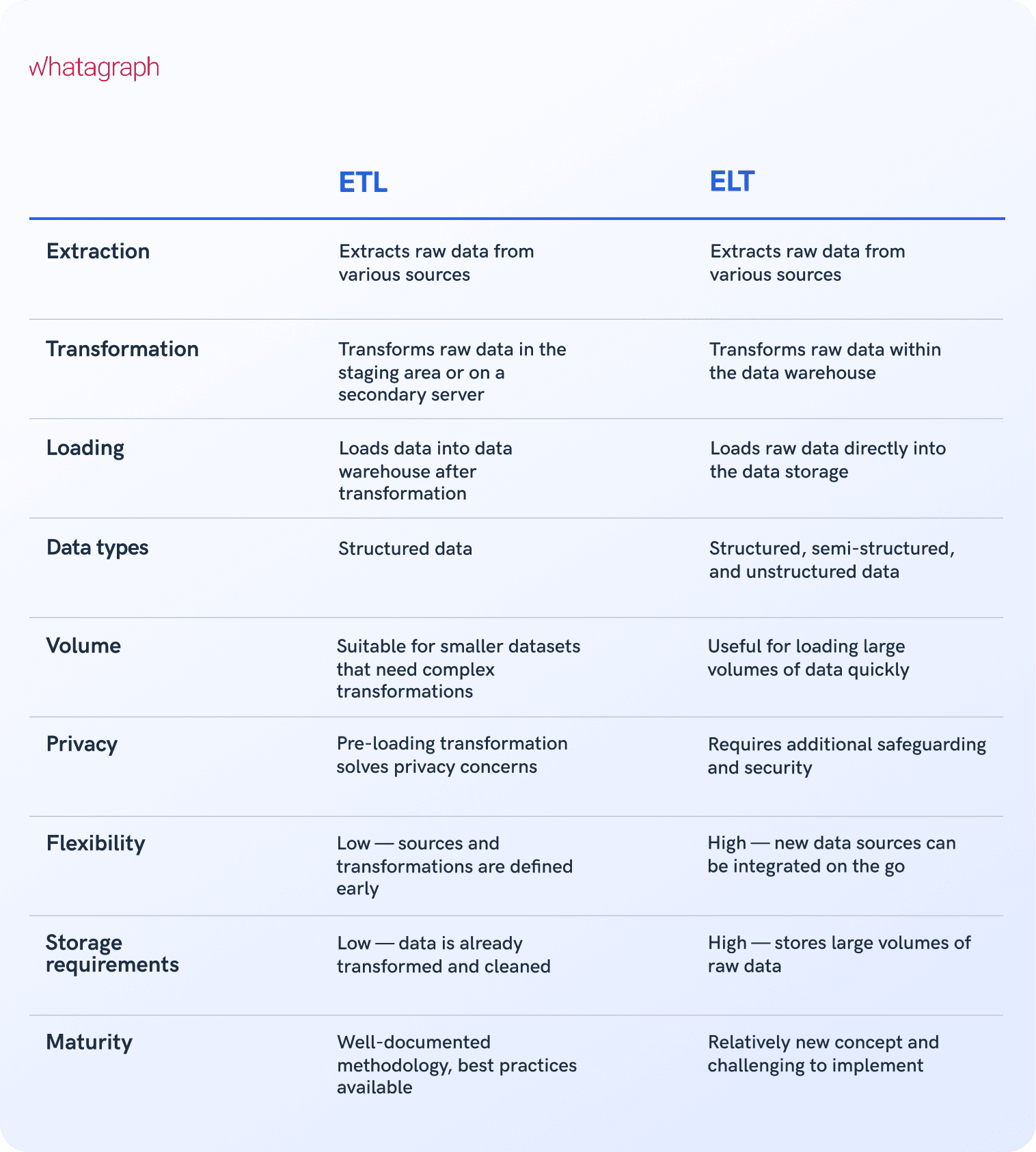
What is the difference between ETL and ELT?
The biggest difference between ETL and ELT (extract, load, transfer) processes is the difference in the order of operations. In the ELT process, data is exported from the source location, but instead of loading it to a staging area for data transformation, raw data is loaded directly to the target system to be transformed as needed.
Both processes depend on a variety of data repositories such as databases, data warehouses, and data lakes, but each process has its specifics.
Wrapping up
To stay competitive, businesses must make the most out of their data. Luckily, extracting useful information from your data does not require time-consuming manual work.
By using an ETL solution, you can save time and money while making your data less vulnerable to security risks and human error.
Whatagraph allows non-tech staff to move complex data sets from a range of marketing data tools effortlessly and safely.
If you’re looking for an easy-to-use solution to connect data from various marketing sources, keep your marketing data safe, or want to visualize your BigQuery data, book a demo call and find out how Whatagraph can help.
Published on Feb 14 2023
WRITTEN BY
Nikola Gemes
Nikola is a content marketer at Whatagraph with extensive writing experience in SaaS and tech niches. With a background in content management apps and composable architectures, it's his job to educate readers about the latest developments in the world of marketing data, data warehousing, headless architectures, and federated content platforms.