What is a Marketing Data Warehouse and Why Do You Need One?
Tools like Asana, Close, Facebook Ads, NetSuite, Salesforce, Zoho, and hundreds of other apps each collect different data on your customers. All those apps are designed to make our work easier. But in reality, teams end up with separate data silos. This makes it difficult to use data from individual tools in planning future marketing strategies. So how do you get a 360° customer view? By using a marketing data warehouse. Let’s find out what exactly a marketing data warehouse is and how your business can benefit from it.

Dec 09 2022●9 min read








What is a marketing data warehouse?
A marketing data warehouse is a cloud-based data storage system that allows teams to consolidate data from multiple sources, such as marketing platforms, websites, analytics tools, and your CRM.
The number of marketing and sales tools has grown rapidly. According to the HubSpot State of Marketing Report, about 62% of marketers use built-in marketing or CRM software for reporting.
And that’s just to begin with.
There are analytics platforms, social media platforms, emailing apps, a CMS, and probably a few more. Compared to in-house data storage and analytics solutions, such as martech tools and turnkey business intelligence (BI) dashboards, data warehouses provide relatively inexpensive and scalable storage that can grow with your business.
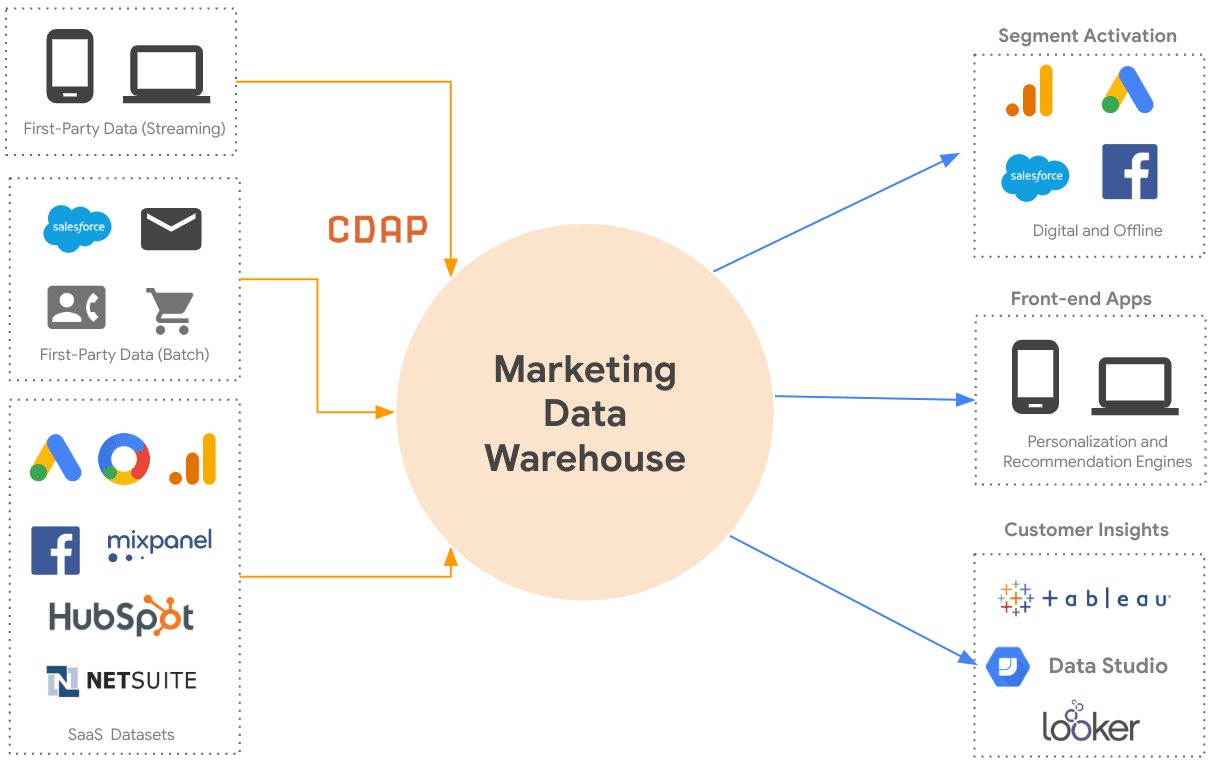
Marketing data warehouses can store large amounts of data, so companies often use one data warehouse for both their marketing data and other data. This is why it's fundamental to understand the difference between a data lake vs data warehouse. In both cases, data warehouse solutions help companies make the right business decisions.
When designing Whatagraph’s data transfer feature, we wanted to make data warehousing easier for two types of users:
- Small non-tech teams
- Marketing agencies that handle hundreds of clients, each with their own data stacks
In both cases, Whatagraph saves the time needed to load data from multiple sources to Google BigQuery.
We simplified the data transfer process to the point-and-click level so anyone can do it.
No code knowledge or data engineering is required – just connect your BigQuery account, select the source and run the transfer.

Why do you need a data warehouse?
As businesses are becoming more interested in customer data, the number of marketing tools and platforms is growing.
Still, getting an overview across different accounts, social media, content, CRM, etc. can be incredibly difficult because data is siloed in these systems and there’s no single source of truth.
You can technically use Excel or Google Sheets to stitch Google Analytics data together, but it's tedious manual work that is prone to human error. This inevitably limits the capabilities of your team to scale up their reporting, as well as the type of datasets they can pull.
So, what benefits does data warehousing offer?
Insight from different sources
For example, let’s say that your team needs to answer the question “What is the number of leads from Facebook?” You can easily do this by checking one of the pre-built reports from these platforms to understand that. A tool like HubSpot can easily answer questions like “How many subscriptions were created in May?”
But if you want to know “What caused a 20% drop in subscriptions in May compared to the previous month?”, the system needs to understand what other activities took place on different platforms in that period.
Getting real time answers like those requires you to look at the data holistically, as different factors in your data pipeline might have affected your sales.
And that is what marketing data warehousing does.
It gives you unlimited scalability and a much more resilient and error-free platform than Excel sheets.
It aggregates your data that is coming from multiple sources to become the ultimate data source for decision making and creating actionable insights in real time.

Single source of truth
Everyone in your business will have the same metrics to work with. Since those metrics are calculated the same way and come from one location, this prevents much confusion and avoids conflicts between teams and roles. This is especially important because data warehouses contain large amounts of historical data collected over months or years.
A complete overview of the customer journey
No single tool knows everything about your users, so looking at their individual dashboards doesn't show you the complete user journey in a central location.
But when you rely on structured data that is combined from all tools and sources, online and offline, you get a much more detailed picture of the entire user journey. At the end of the day, this allows for much more accurate long-term metrics, such as the user's lifetime value.
Time to insight
When you use a cloud-based marketing data warehouse, you don’t need expensive on-premises hardware such as a physical data center to set up your marketing data pipeline.
Just choose your data warehouse, such as BigQuery, Snowflake or Amazon Redshift, and start moving your data with a fully managed pipeline in real time.
Even better, use a reporting tool that doesn’t need any additional data aggregators, such as Whatagraph.
Getting started with Whatagraph takes only a few clicks.
Add your data sources from Google Ads, Facebook Ads, Shopify or more than 40 other integrations and optimize your insights.
What is more, Whatagraph comes with instant report templates that provide you with insightful data analytics in minutes, for all your stakeholders.
Access to raw data
Most marketing dashboard interfaces show you aggregated data and calculated metrics. This not only limits you to do your own calculations, but data from different tools also never match.
However, when you work with raw data, you define your own aggregation and calculation protocols for the entire organization.
Visualization and BI support
Not all marketing tools are compatible with major data visualization and BI tools. On the other hand, data warehouses like BigQuery, have a native integration with almost every reputable BI and visualization tool.
Data warehouse vs. database vs. data lake vs. data mart
Although intelligent data analytics tools, most marketing teams still rely on simple spreadsheets and dashboard tools for data storage, analysis, visualization, and reporting on their marketing campaigns.
A 2022 survey has revealed that almost 80% of marketers find spreadsheets critical for their work. In other words, that’s what they spend the most time working with.
The problem is that spreadsheets and other self-service dashboards just aren’t built to handle ever-growing amounts of marketing data in real time.
That’s where data warehouses, databases, data lakes, and data marts come into play.
However, these data management terms are often used interchangeably and incorrectly, so let’s break them down and explain their respective use cases.
Data warehouse
A data warehouse is a cloud-based platform that allows data scientists, developers who build ETL pipelines, or marketing teams to store and analyze structured data across channels and departments. It usually consists of tables and uses SQL as the query language.
- Type of data: Structured
- Number of sources: Many
- Capacity: Small to large
- Cost: Low to medium
- Data access: SQL APIs
Database
A database is a highly organized collection of structured data that teams can easily access, manage and update. Unlike cloud-based data warehouses, a database usually contains only mutually-related big data. An example of a database is your CRM – it stores information about your customers and leads.
- Type of data: Structured
- Number of sources: Few
- Capacity: Small to medium
- Cost: High
- Data access: Database management system
Data lake
A data lake is a central repository of data where teams can store data in its raw format, both structured and unstructured. The best way to describe a data lake is in your Google Drive folder. If you’re a digital content creator like me, it’s full of images, text docs, spreadsheets, and audio podcasts.
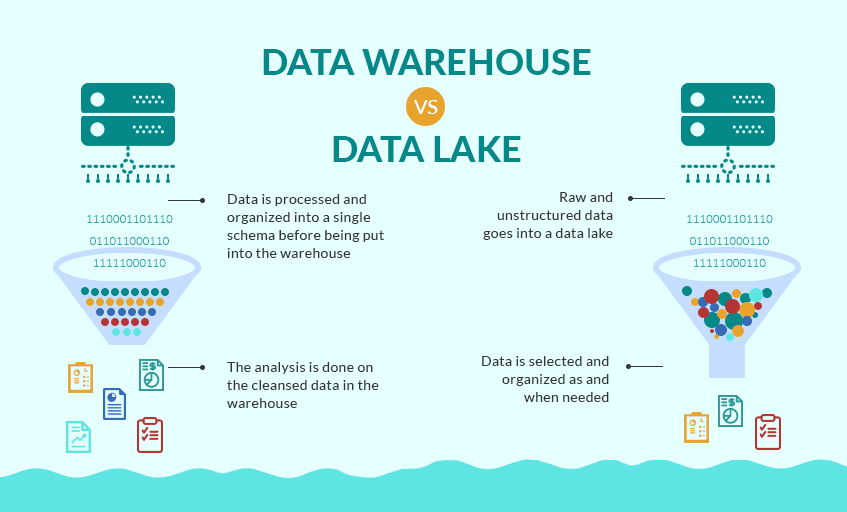
- Type of data: Unstructured and structured
- Number of sources: Many
- Capacity: Large
- Cost: Low
- Data access: CSV files
A poorly managed data lake can over time turn into a data swamp.
Data mart
A data mart is a subdivision of a data warehouse that serves a specific business line. For example, if you’re storing data from other departments in the same data warehouse, your “marketing data warehouse” is in fact a data mart. By offering more structure, data marts can help users solve what's often quoted as the biggest data warehousing challenge: managing and optimizing the structure.
- Type of data: Structured
- Number of sources: Many
- Capacity: Medium
- Cost: Medium
- Data access: SQL
So what can we conclude?
A data warehouse is an excellent solution for the long-term storage of all your marketing data:
1. It can store data from many sources.
2. Its capacity is scalable according to your needs.
3. The data storage cost is also scalable – you pay based on the volume of data.
4. The data is structured, which means easier to query and analyze in real-time.
Wrapping up
I hope this post helped you understand the concept of a marketing data warehouse and why every digital marketing team could use one.
If you’d like to try a marketing data warehouse, but don’t know where to start, I recommend you try out Whatagraph.
Whatagraph allows you to collect and analyze data from 40+ marketing channels, and the best thing is that you don't need any other tool to make it work.
Use it to create visually-appealing real time reports of the most important metrics and show results behind your campaigns.
Whatagraph pretty much automates your reporting and brings your marketing analytics capabilities on a whole new level.
The app is intuitive and easy to use but if you ever get stuck, there’s 24/5 support to help you out.
Book a demo call with our product experts and find out how else Whatagraph can help you grow your business.
Published on Dec 09 2022
WRITTEN BY
Nikola GemesNikola is a content marketer at Whatagraph with extensive writing experience in SaaS and tech niches. With a background in content management apps and composable architectures, it's his job to educate readers about the latest developments in the world of marketing data, data warehousing, headless architectures, and federated content platforms.