Setting up Your Marketing Data Warehouse: 5 Key Steps for Success
Data warehousing has changed the data analytics game for many marketers by giving them a tool to gather insights from disparate data sources, keep the data safe from individual platform policies, and streamline reporting.
But how do you set up a data warehousing operation and bring unified insight to decision-makers?

May 04 2023 ● 6 min read

What is a marketing data warehouse, and why do you need one?
A marketing data warehouse is a system that can store a vast amount of data from various marketing platforms. Data warehouses are often used to combine different data sources in order to analyze data and achieve business intelligence through reports and dashboards.
Marketing teams can use data warehouses to store their and their clients’ data which comes in many forms, from raw unstructured data to cleansed, filtered, and aggregated data — thanks to the ETL process.
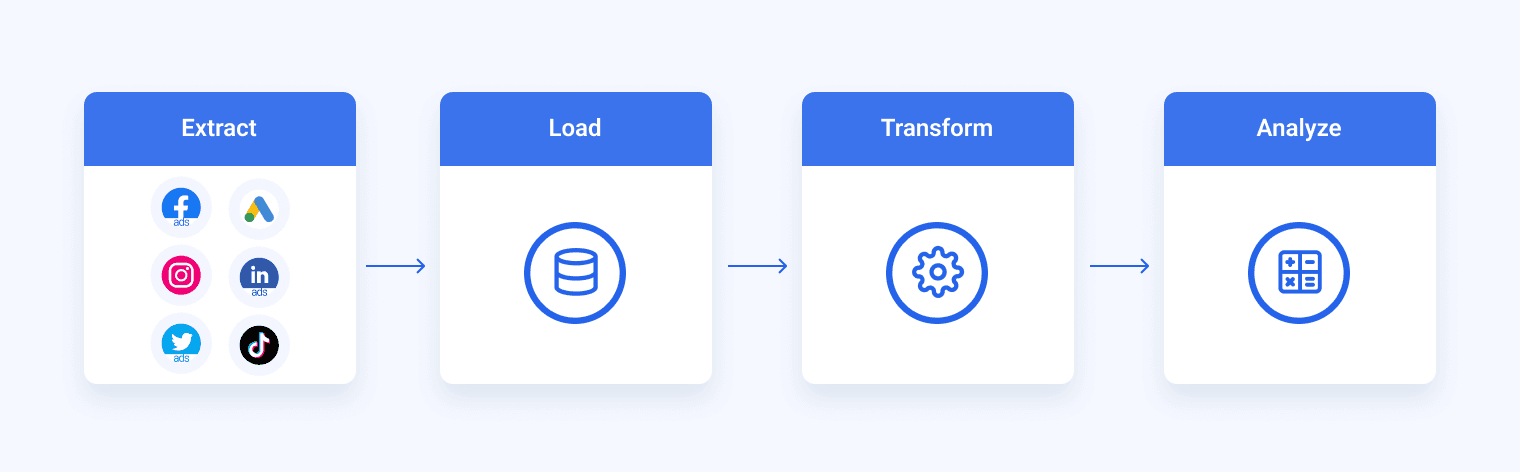
ETL stands for extract, transfer, load and refers to three steps of loading data into a warehouse:
- Extract data from connected sources
- Transform the data through a series of rules and operations to make it compatible
- Load the data into a data warehouse.
In the past, you’d need a data engineer to set up and run the ETL, but since the advent of ETL tools, data warehousing has been simplified so much that even non-tech marketing teams can do it.
The automation of the process is one of the reasons behind the growing popularity of data warehouses such as Microsoft Azure, Google BigQuery, Snowflake, and Amazon Redshift.
And here are the other reasons why your clients can benefit from a data warehouse.
- Deeper insights: Data from different sources is consolidated and highly structured, which enables in-depth data analysis in a relatively simple and straightforward way, even if you have large amounts of historical data from different sources.
- Improved security: Individual platforms may shift their data collection policies, change storage rules, or discontinue services. By replicating all their data in a data warehouse, your clients can take full ownership of their marketing data and be safe from unexpected events.
- Centralized data source: It’s much easier to be on the same page when everyone in your agency and client’s company has the same data to work with. No need to pursue data from disparate platforms and try to compare them in one place.
- Mid-step to visualization: When all the client’s data is in data warehouse, you can easily report on and compare different data points using graphs, charts, tables, or any other visualization widget. For example, you can use Whatagraph to easily move your client’s data to a data warehouse and visualize it in the form of a report or dashboard.

5 steps to setting up a marketing data warehouse
Step 1: Determine your business needs
As discussed in the above-mentioned reasons why you may need a data warehouse, companies often use them to solve a particular problem, such as how to generate more revenue, mitigate regulatory risk, improve board and client-level reporting, etc.
You need to make your requirements clear by creating reporting stories that make you think of the final outcome.
For example:
As a marketing manager, you need to know the number of products the customer purchased last year, so you can target them with an upsell offer.
From this story, we can learn that you need to aggregate the number of products per customer based on the previous year’s sales.
Now go ahead and create an entire catalog of reporting stores that will help you determine your business data requirements.
While interviewing business users, you should also establish communication with your database administrators and source system experts to determine if the information you currently have is enough to meet your business requirements, such as:
- Supported operating systems
- Data update frequency
- Availability of historical data
- Tools that are used to access and analyze information
- Types of insights that will be generated
- Support for machine learning
But what if you don’t have the infrastructure or technical staff that would build a data warehouse?
Read on and find out.
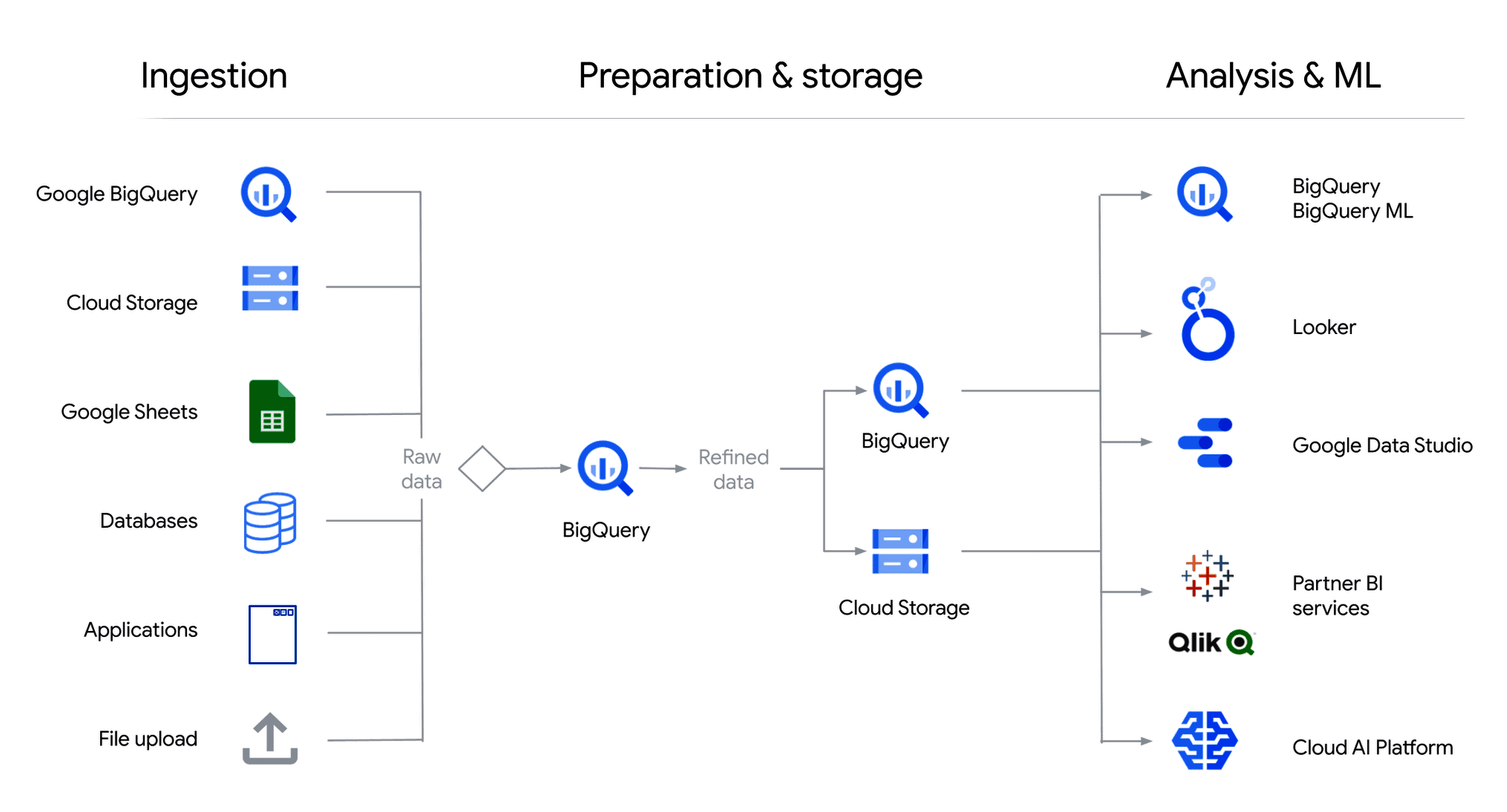
Step 2: Conceptualization and choosing a data warehouse tool
After you’ve defined the scope of your future data warehouse solution, you need to evaluate and select the optimal technology for each of the architectural components: staging area, data storage area, etc. While assembling the tech stack, you need to consider:
- Your current technological environment
- Planned technological direction strategy
- Technical competencies of the in-house IT team
- Specific data security requirements
At this point, you should also define the deployment option:
- On-premises (Oracle, Microsoft SQL Server, etc.)
- Cloud (Amazon S3, Google Cloud, etc.) or
- Hybrid
Which one you choose depends on several factors, such as data volume, data nature, costs, security requirements, number of users and their location, as well as system availability.
For example, if you don’t have an in-house IT team, it makes more sense to go with a fully managed data warehouse such as Google BigQuery.
Step 3: Designing the data warehouse environment
At one point in designing your data warehouse, you need to define your data sources and analyze the information that is stored there. This includes data types that are available and the volume of new data created daily, including its quality, sensitivity, and refresh frequency.
The next step is to arrange the company's data into a series of logical relationships called entities (real-world objects) and attributes (characteristics that define them). Data experts use entity-relationship modeling for normalized schema — used for relational databases, and the star schema — used for dimensional modeling.
In the next step, the logical data models are converted into database structures, for example, entities into fact tables, attributes into columns, relationships into foreign key constraints, etc.
When data modeling is finished, the first step is to design the data staging area that would provide your data warehouse design with quality aggregated data in the first place and also to define and control the source-to-target flow in every subsequent data transfer.

Step 4: Developing and launching a data warehouse
In this step, your team needs to customize and configure selected technologies such as the data warehousing platform, data transformation technologies, data security software, etc. After that, you need to develop data pipelines and implement data security.
When all the key components are introduced, you need to integrate them with the existing data infrastructure, including data sources, BI tools, analytics software, a data lake (if you have one), as well as each other so you can migrate this data afterward.
Before the launch, you need to ensure that your end users can handle the new technology environment, which means all of them understand what information is available, what it means, how to access it, and what analytical tools to use.
Finally, you need to:
- Test the data warehouse performance, including the ETL process
- Verify data quality (legibility, completeness, security, etc.)
- Ensure users have access to a data warehouse.
Again, if your end users are not tech-savvy, a fully managed data warehouse and an automated ETL process, such as Whatagraph provides, would take a lot of guesswork and unknowns out of the equation.
Step 5: Maintaining a data warehouse
Once deployed, you need to shift focus from the data warehouse to your business users and provide ongoing support and education. Over time, you need to measure the data warehouse performance metrics and user satisfaction. This will ensure the long-term health and scaling of your data warehouse, while minimizing the common data warehouse difficulties that users often encounter.
Conclusion
A modern data warehouse project can help your organization accomplish many of its data management and analysis workflows and solve issues like broken data silos, real-time analytics, interactive reporting, and safeguarding historical data.
Still, building your own data warehouse architecture using existing technologies such as BigQuery, Azure Synapse, or AWS requires skilled data migration experts and close cooperation between IT and business analysts.
That’s why for most in-house teams and marketing agencies, it’s much more feasible to consider a fully managed, cloud-based data warehouse and use an automated ETL solution such as Whatagraph.
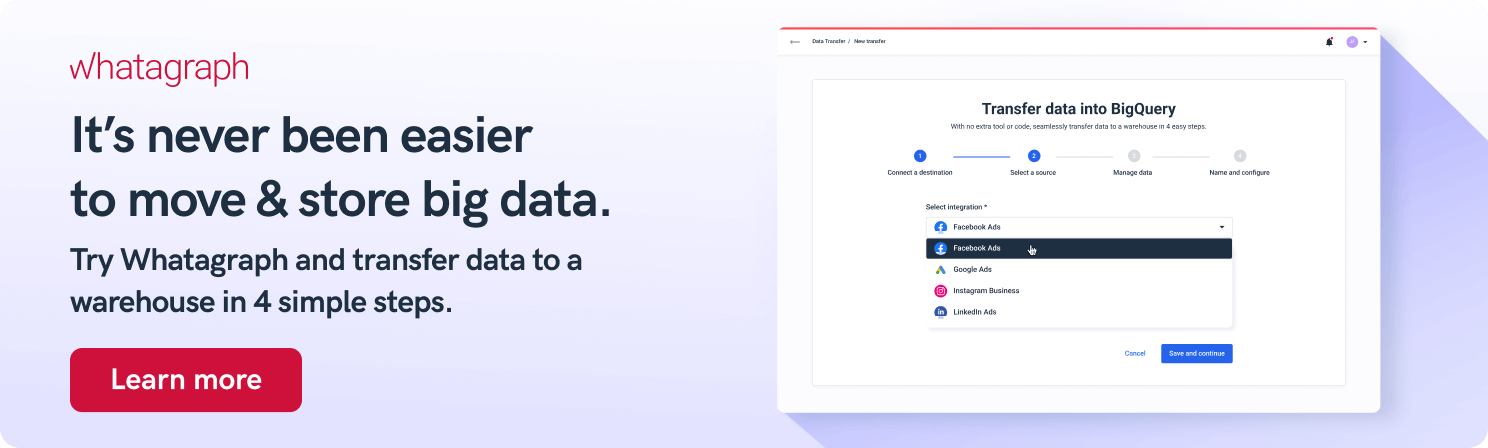
Whatagraph is an ETL tool that allows users to load data from popular marketing platforms to a Google BigQuery in just four steps:
- Connect the destination
- Choose the integration
- Set the schema
- Schedule the transfer
This means you can set up a data flow with nothing more than a few clicks as you go through these intuitive steps.
No data engineering or setting up schemas for every transfer. Just schedule the data flow and set the whole process on autopilot.
If your organization or clients have vast amounts of big data across multiple platforms, you can use Whatagraph to take full ownership of that data.
Once in BigQuery, you can report on your consolidated data using Whatagraph’s visualization feature.
Find out more about the easy way to use a data warehouse and enjoy code-free data transfers to BigQuery with Whatagraph.
Published on May 03 2023
WRITTEN BY
Nikola GemesNikola is a content marketer at Whatagraph with extensive writing experience in SaaS and tech niches. With a background in content management apps and composable architectures, it's his job to educate readers about the latest developments in the world of marketing data, data warehousing, headless architectures, and federated content platforms.